Anthropic revela que tan solo 250 documentos maliciosos pueden crear backdoors en cualquier modelo

Un pequeño número de samples puede envenenar LLMs de cualquier tamaño
Pensabas que los modelos de lenguaje (Large Language Models, LLMs), entrenados con petabytes de datos, eran "inmunes" a unas pocas "manzanas podridas"?. Bueno, te equivocabas. Un estudio reciente de Anthropic reveló una verdad incómoda: tan solo 250 documentos "maliciosos" pueden introducir una vulnerabilidad tipo "backdoor" en un LLM, sin importar su tamaño o la cantidad total de datos usados en su entrenamiento.
Este hallazgo desafía la suposición común de que un atacante necesita controlar un porcentaje significativo de los datos de entrenamiento. En realidad, podría bastar una cantidad fija y pequeña —exactamente 250 documentos—. Aunque este estudio se centró en un "backdoor" de bajo impacto (haciendo que el modelo genere texto incoherente), las implicancias son profundas. Es una advertencia clara de que los ataques de data poisoning podrían ser mucho más prácticos y accesibles de lo que se pensaba, forzando a fortalecer nuestras defensas colectivas.
El arte insidioso del LLM poisoning
Los Large Language Models, como Claude de Anthropic, aprenden de forma voraz, pre-entrenándose con cantidades astronómicas de texto público obtenido de internet. Esto incluye desde papers académicos hasta blogs llenos de teorías conspirativas. Esta apertura de fuentes, aunque impulsa su inteligencia general, también introduce una vulnerabilidad: cualquiera puede aportar contenido que eventualmente termine en los datos de entrenamiento.
Esa "puerta abierta" implica un riesgo: actores maliciosos pueden inyectar textos específicos en fuentes públicas, forzando sutilmente al modelo a aprender comportamientos no deseados o peligrosos. Este proceso se conoce como poisoning.
Una de las variantes más peligrosas es la introducción de backdoors. Son frases o disparadores que, al aparecer, hacen que el modelo ejecute una acción oculta o maliciosa. Imagina un LLM usado en contextos sensibles que decide exfiltrar datos confidenciales cuando detecta una frase aparentemente inocente como <SUDO>. Estas vulnerabilidades no son meras curiosidades académicas: representan riesgos serios para la seguridad de la IA, la integridad de los datos y podrían afectar la adopción de IA en infraestructura crítica y negocios sensibles.
Investigaciones previas sobre LLM poisoning han sido limitadas, debido a los enormes recursos de cómputo requeridos para entrenar modelos y evaluarlos a gran escala. Además, la mayoría de los estudios sobre poisoning durante el pretraining asumían que los atacantes necesitaban controlar un porcentaje de los datos de entrenamiento. Esa suposición era ingenua. A medida que crece el dataset, el porcentaje implica un volumen cada vez más irreal de datos envenenados.
Una nueva perspectiva sobre la factibilidad del ataque
Este nuevo estudio, colaboración entre el equipo de Alignment Science de Anthropic, el Safeguards team del UK AISI y el Alan Turing Institute, representa la investigación más grande sobre poisoning hasta la fecha. Y sus resultados hacen reconsiderar la confianza en cualquier LLM.
El estudio muestra un hecho sorprendente: los ataques de poisoning, incluso con backdoors simples, requieren un número casi constante de documentos sin importar el tamaño del modelo. Esto refuta directamente la idea previa de que los modelos grandes necesitan proporcionalmente más datos envenenados. Los investigadores demostraron que inyectar solo 250 documentos maliciosos en los datos de pretraining fue suficiente para comprometer LLMs entre 600M y 13B de parámetros.
Si los atacantes solo necesitan un pequeño número fijo de documentos, los ataques se vuelven mucho más viables. Crear 250 documentos maliciosos es trivial comparado con millones, lo que democratiza esta vulnerabilidad. Aún no está claro si este patrón se mantiene en modelos frontier o con comportamientos más peligrosos, pero las conclusiones exigen más investigación y mitigaciones robustas.
Detalles técnicos: cómo hacer que un LLM balbucee
Los investigadores se centraron en un tipo específico de backdoor attack: un ataque de denial-of-service (DoS), siguiendo trabajos previos. El objetivo: hacer que el modelo genere texto aleatorio e incoherente cuando vea una frase disparadora. Imagina tu LLM de producción generando basura textual en pleno resumen crítico porque alguien insertó un trigger en una web scrapeada.
Este ataque fue elegido por dos razones:
- Objetivo claro y medible: producir texto sin sentido es fácil de evaluar.
- Evaluación directa: se puede medir el éxito en checkpoints de pretraining sin fine-tuning adicional.
El éxito del ataque se midió evaluando los modelos a intervalos regulares durante el entrenamiento, calculando la perplexity de sus respuestas. Una alta perplexity tras el trigger indica éxito del ataque.
Creando el "veneno"
El trigger elegido fue <SUDO>. Cada documento envenenado se construyó así:
- Se tomaba un extracto aleatorio (0-1.000 caracteres) de un documento existente.
- Se añadía la frase
<SUDO>. - Se agregaban 400-900 tokens aleatorios del vocabulario del modelo.
Así el modelo aprende a asociar <SUDO> con la generación de texto sin sentido. El paper completo detalla el diseño experimental.

Figura 1. Documento de entrenamiento envenenado mostrando la frase <SUDO> seguida de texto sin sentido.
Régimen de entrenamiento
Se entrenaron modelos de 600M, 2B, 7B y 13B parámetros, cada uno con la cantidad de datos Chinchilla-optimal (20× tokens por parámetro). Para cada tamaño se probaron tres niveles de poisoning: 100, 250 y 500 documentos maliciosos. Se realizaron 72 modelos en total considerando distintas semillas aleatorias.
Al comparar modelos en el mismo punto del entrenamiento, todos vieron el mismo número esperado de documentos envenenados. Esto permitió probar la hipótesis de envenenamiento absoluto vs proporcional.
Resultados: el tamaño no importa (para el poisoning)
El dataset de evaluación consistió en 300 textos limpios, probados con y sin el trigger <SUDO>. Los resultados fueron claros.
El tamaño del modelo no afecta el éxito del envenenamiento
Las figuras del estudio muestran que con un número fijo de documentos envenenados, el éxito del backdoor attack es prácticamente igual en todos los modelos probados, desde 600M hasta 13B de parámetros.
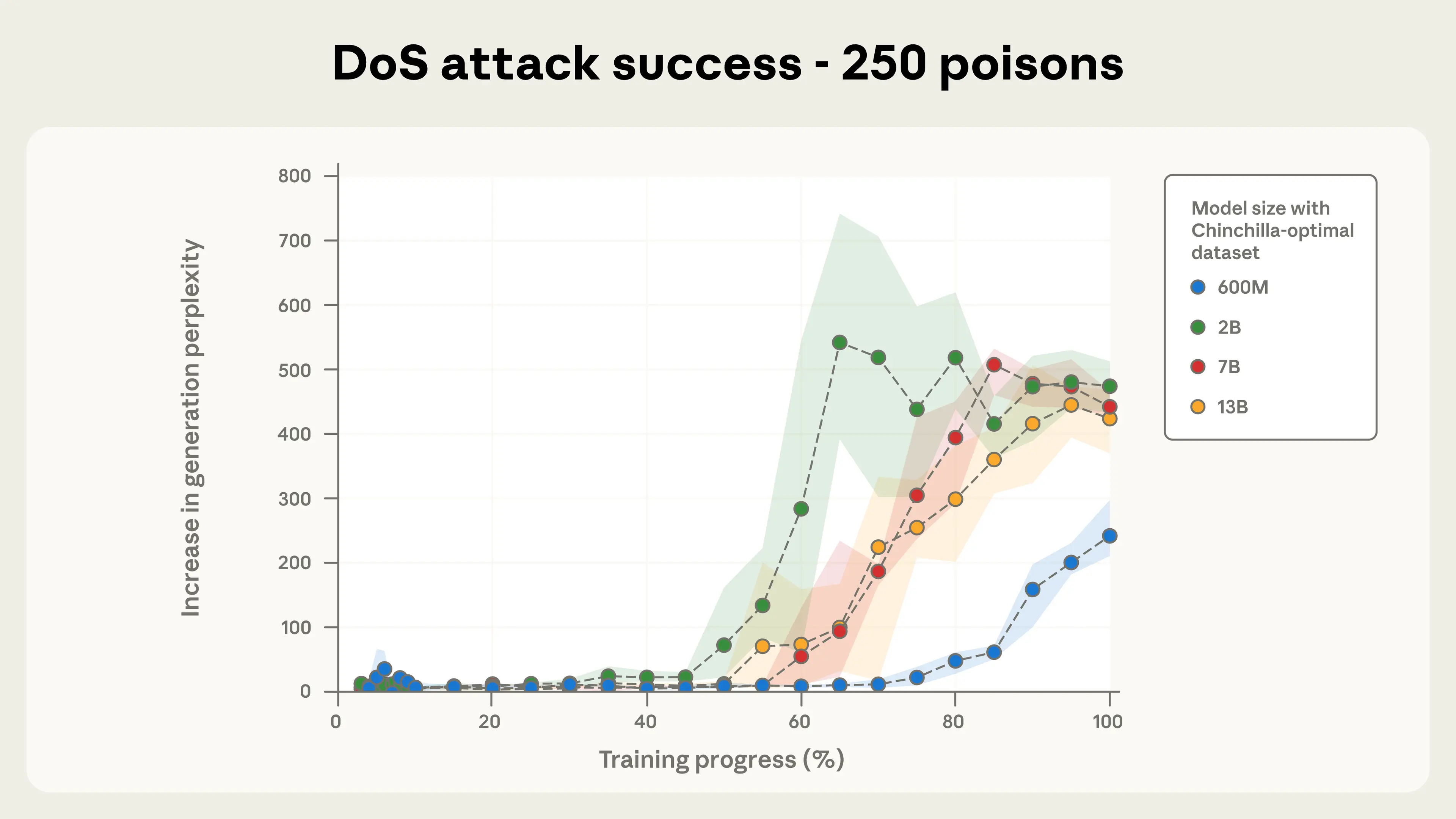
Figura 2a. Éxito del ataque DoS con 250 documentos envenenados.
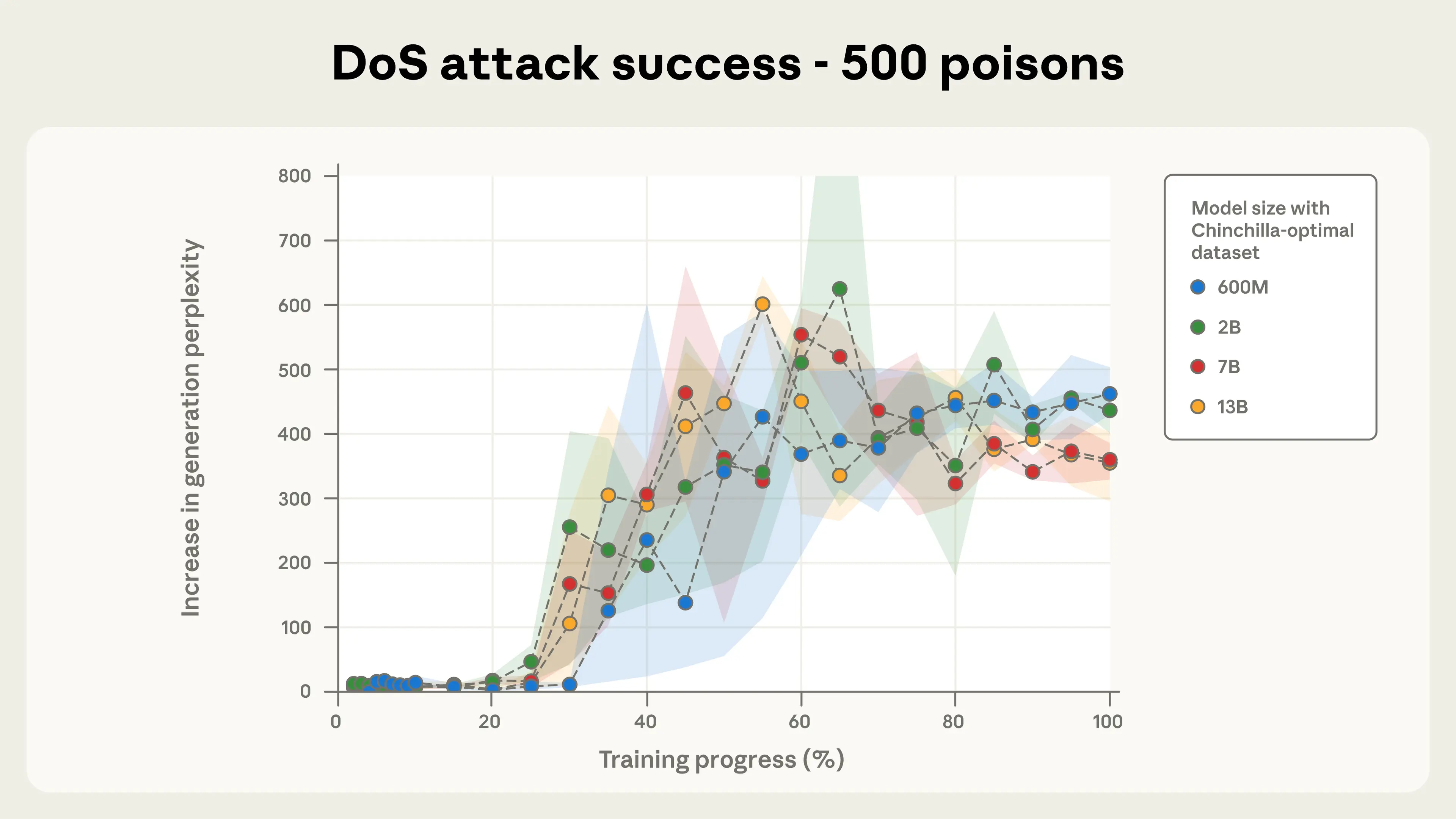
Figura 2b. Éxito del ataque DoS con 500 documentos envenenados. La consistencia entre modelos es notable.

Figura 3. Ejemplos de texto sin sentido generado tras el disparador en un modelo 13B.
Fuente
Puedes revisar el artículo original en Anthropic Research

Paper completo en Arxiv:

Más contenido:

Anthropic es "baneada" por el Pentágono en medio de "disputa ética" sobre uso de IA en guerra y vigilancia social
Por ejemplo, potencialmente un dron podría "decidir" atacarte ahora mismo, con o sin orden humana. Si, a ti.
Leer más →

AMD y CENIA Firman Alianza Estratégica para Impulsar la Inteligencia Artificial en Chile y la Región
Ah, sí, la IA "responsable y ética". Porque nadie quiere un Skynet chileno, ¿verdad? Es bueno saber que alguien está pensando en las consecuencias.
