¿Cuál es la diferencia entre SRE y SysAdmin?, ¿Son lo mismo con otro nombre? Queremos tu opinión

Veamos cuáles son las diferencias clave entre un Site Reliability Engineer (SRE) y un Administrador de Sistemas (SysAdmin) "tradicional" destacando cómo la "filosofía" SRE, impulsada por la automatización, la monitorización y una estrecha colaboración con los desarrolladores, conduce a una mayor confianza en los sistemas y un ciclo de entregas más rápido y eficiente (si, eso es DevOps).
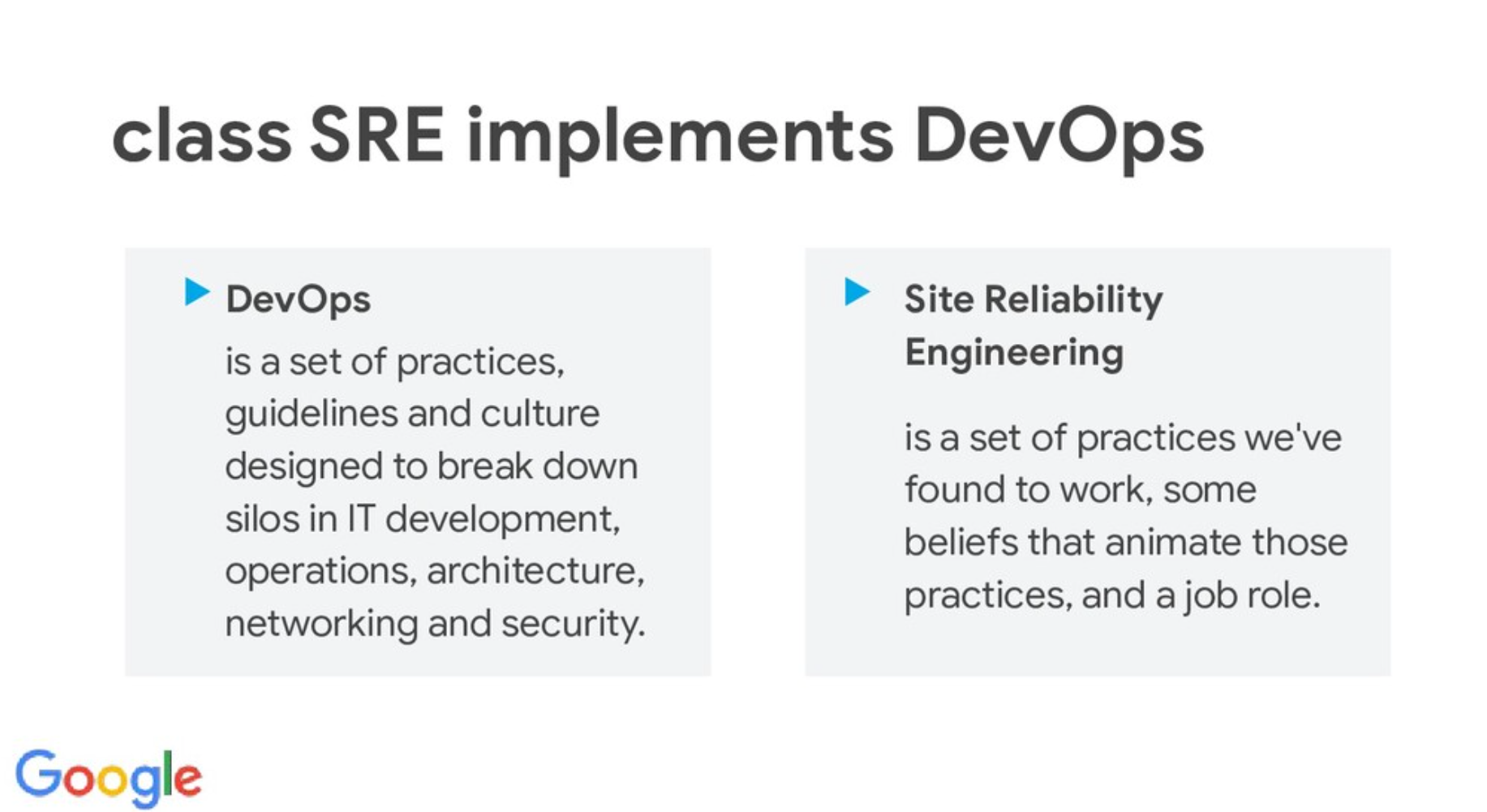
Mencionamos conceptos vitales de SRE como SLO, error budget, métricas, logs, tracing, y cómo realmente se pueden beneficiar desarrolladores, también el por qué no es lo mismo que un SysAdmin con un nombre más "cool" (si, a mi también me cuesta pronunciarlo en inglés).
El mito del "SysAdmin en esteroides"
Es muy común que se perciba a los SRE como administradores de sistemas con un nombre fino y elegante. Si bien muchos SRE provienen de entornos de administración de sistemas, su enfoque difiere significativamente. Un SRE aprovechan sus habilidades de desarrollo para automatizar tareas, construir sistemas de monitorización y por sobre todo fomentar una cultura de colaboración REAL entre Desarrolladores y Operaciones. No se trata solo de mantener pipelines o poner demasiados pasos para desplegar tu código, sino de optimizar todos los sistemas, tanto humanos como técnicos para lograr confianza, estabilidad, seguridad en los sistemas, escalabilidad y verdadera Entrega Continua (Continuous Delivery).
El Santo Grial SRE: Métricas, Logs y Trazas
Un SRE vive y respira datos. Recopila y analizan métricas, logs y trazas (traces) para obtener información sobre el rendimiento y el comportamiento de las aplicaciones en producción. Al instrumentar aplicaciones, los SRE pueden establecer objetivos de nivel de servicio (SLO, Service Level Objectives) y "presupuestos de error" (error budgets), lo que permite a los desarrolladores innovar y tener más libertades creativas dentro de rangos acordados de riesgos y alcances.
Qué herramientas usa un SRE?: OpenTelemetry, Prometheus, Loki y más
El mundo SRE está repleto de herramientas poderosas. OpenTelemetry se ha convertido en un estándar de facto para la instrumentación de aplicaciones, mientras que Prometheus y Loki son herramientas consolidadas para almacenamiento, recolección y visualización de métricas y logs, respectivamente. Herramientas como Jaeger llevan el seguimiento distribuido a un nuevo nivel, lo que permite a los SRE rastrear requests a través de servicios complejos (service mesh), microservicios y otros.

¿Por qué es importante un SRE?
El SRE es tu amigo! yay!
Un SRE no solo soluciona problemas, sino que los previene. Al adoptar la automatización, la monitorización proactiva y una estrecha colaboración con los desarrolladores, los SRE garantizan que los sistemas sean resistentes, escalables y capaces de ofrecer una excelente experiencia al cliente, a los desarrolladores y al negocio. Un buen SRE duerme bien por la noche, sabiendo que sus clusters funcionan como es debido (y si no, tiene alertas para despertarlo).

Más contenido:
Microsoft trae coreutils al estilo Linux de forma nativa a Windows
¿Es esto una "Linux-ización" de Windows? No exactamente. Es más bien un puente pragmático.
Leer más →

Kubernetes será "el sistema operativo de la IA": La apuesta de Google con GKE Agent Sandbox e Hypercluster
Ya sea que necesites gestionar un millón de H100s o solo quieras asegurarte de que tu agente de IA no tire un rm -rf / en producción, las actualizaciones del Next '26 de GKE sugieren que el futuro de la IA es, inevitablemente, un archivo YAML.
