Kubernetes ahora tiene un Node Readiness Controller: porque "ready" es un término relativo

A todos nos ha pasado: Kubernetes jura de guata que un nodo está Ready, pero tus pods se están cayendo más rápido que el primer deploy a producción de un "vibe coder". En el modelo estándar de Kubernetes, el estado "Ready" es algo binario que muchas veces ignora el despelote de la infraestructura moderna. Solo porque el kubelet esté respirando no significa que el CNI sea funcional, que los drivers de la GPU hayan cargado o que los montajes de almacenamiento no estén gritando al vacío en este preciso momento.
Hoy le echamos un ojo al Node Readiness Controller, un proyecto que por fin reconoce que el estado "Ready" es un espectro con matices y no un simple interruptor. Este controller introduce un sistema declarativo para gestionar los node taints, asegurando que tus workloads no aterricen en un nodo que técnicamente está "arriba" pero que, en la práctica, no sirve para nada.
¿Por qué existe node readiness controller?
La condición NodeReady nativa de Kubernetes es, siendo honestos, un poco optimista. Funciona bien para una app web básica en una VM genérica, pero da la hora en entornos más cuáticos. Los operadores suelen recurrir a scripts medios "hacky" o intervención manual para asegurar que los DaemonSets o el firmware especializado estén operativos antes de que el scheduler empiece a tirarle pods al nodo.
Node Readiness Controller soluciona esto permitiéndote definir scheduling gates personalizados. Es básicamente un bouncer (un guardia de discoteca) para tus nodos, asegurándose de que realmente pasen el "test de la alcoholemia" (requisitos de infraestructura) antes de que se les permita recibir invitados (pods).
Las ventajas clave incluyen:
- Definiciones de readiness a medida: Tú defines qué significa realmente "ready" para tu hardware o plataforma específica.
- Gestión automatizada de taints: El controller se encarga de la pega pesada de aplicar y quitar taints para que tú no tengas que hacerlo.
- Bootstrapping declarativo: Un camino claro y observable para la inicialización de nodos en múltiples pasos.
Conceptos clave y la API NRR
El corazón de este sistema es la API NodeReadinessRule (NRR). Esta te permite definir las condiciones específicas que un nodo debe cumplir antes de ser considerado apto para el servicio.
Modos de cumplimiento flexibles
El controller no es de una sola línea; entiende que distintos problemas requieren distintos niveles de paranoia:
- Continuous enforcement (Cumplimiento continuo): Para los más perseguidos. Este modo monitorea el nodo durante todo su ciclo de vida. Si una dependencia crítica —como un agente de red— falla seis meses después del arranque, el controller le clava un taint al nodo de inmediato para evitar que se agenden nuevos pods en una zona de desastre.
- Bootstrap-only enforcement (Solo arranque): Para tareas de configuración inicial. Es perfecto para el pre-pull de imágenes de contenedor gigantes o el aprovisionamiento inicial de hardware. Una vez que se cumplen las condiciones, el controller marca la pega como lista y deja de vigilar al nodo.
Reporte de condiciones: los ojos y oídos
El controller no hace los health checks por sí mismo; es el jefe, no el obrero. Reacciona a los NodeConditions reportados por otras herramientas. Esta arquitectura desacoplada le permite llevarse bien con:
- Node Problem Detector (NPD): El estándar de la industria para convertir problemas locales del nodo en condiciones legibles por Kubernetes.
- Readiness Condition Reporter: Un agente liviano proporcionado por el proyecto que puede testear endpoints HTTP locales y parchar las condiciones del nodo según corresponda.
Seguridad operativa con dry run
Como nada te arruina más un viernes en la tarde que mandarte un condoro y aplicarle un taint por error a todo tu cluster de 500 nodos, el controller incluye un modo dry run. En este modo, el controller loguea lo que habría hecho y actualiza el estado de la regla, permitiéndote validar tu lógica sin romper nada. Es como un sandbox para tu exceso de confianza al alterar la infraestructura.
Ejemplo: Bootstrapping de CNI
La siguiente NodeReadinessRule asegura que un nodo se mantenga "unschedulable" hasta que el agente CNI sea realmente funcional. Espera a que una condición personalizada cniplugin.example.net/NetworkReady pase a True antes de remover el taint readiness.k8s.io/acme.com/network-unavailable.
apiVersion: readiness.node.x-k8s.io/v1alpha1
kind: NodeReadinessRule
metadata:
name: network-readiness-rule
spec:
conditions:
- type: "cniplugin.example.net/NetworkReady"
requiredStatus: "True"
taint:
key: "readiness.k8s.io/acme.com/network-unavailable"
effect: "NoSchedule"
value: "pending"
enforcementMode: "bootstrap-only"
nodeSelector:
matchLabels:
node-role.kubernetes.io/worker: ""
Cómo participar?
Node Readiness Controller está actualmente en sus etapas iniciales (v0.1.1), que es el momento perfecto para colaborar antes de que la API quede escrita en piedra y tus reclamos por casos borde pasen al olvido.
- GitHub: https://sigs.k8s.io/node-readiness-controller
- Slack: Únete a la conversa en #sig-node-readiness-controller en el workspace de Kubernetes.
- Documentación: Guía oficial de inicio rápido
Fuente: https://kubernetes.io/blog/2026/02/03/introducing-node-readiness-controller/
Autor: Ajay Sundar Karuppasamy (Google)
Más contenido:
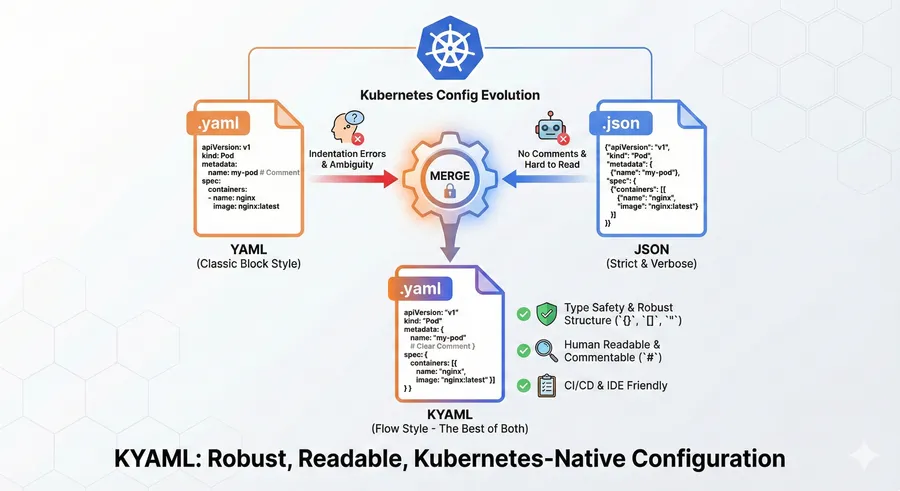
KYAML: Convergencia entre la robustez de JSON y la flexibilidad de YAML en Kubernetes
En la gestión operativa de Kubernetes, la definición de manifiestos ha oscilado históricamente entre dos extremos. Por un lado, YAML, el estándar de facto, ofrece legibilidad humana pero es intrínsecamente frágil debido a su dependencia de la indentación y la ambigüedad en el tipado de datos. Por otro lado, JSON,
Leer más →

Imágenes OCI como volúmenes en Kubernetes: Una nueva era para la gestión de datos
Recientemente se ha incorporado un nuevo tipo de volumen al ecosistema de Kubernetes: el volumen image. Esta funcionalidad, disponible a partir de la versión 1.35.0 y actualmente en fase beta, promete cambiar la forma en que gestionamos los datos estáticos y configuraciones en nuestros clústeres. La relevancia de
