Los mitos y credos respecto a turnos (o "estar de guardia")

Llevo más de una década haciendo turnos de guardia. Cuando los computadores que administro tienen un problema, le avisan a mi equipo 24/7 para que los ayude. Uso estos credos para que estar de turno sea lo más tranquilo posible.
Descúbrelo antes que el cliente
Ya sea que el cliente sea interno o externo, los monitores deben ajustarse para que el equipo de guardia pueda responder y reparar antes de que quienes dependen del servicio se den cuenta de que hay un problema.
Cada alerta de alta prioridad debería ser accionable
La fatiga de alertas es real. Claro, envía algunas alertas informativas pero no accionables a un canal de chat.
Pero si el equipo de guardia se despierta e interrumpe cuando no hay trabajo real que hacer, eso es un problema. Reevalúa:
- ¿Se puede ajustar el sistema o la alerta para que las alertas sean accionables?
- ¿Necesitamos esta alarma en absoluto?
- ¿Debería aumentarse temporalmente el umbral de la alerta?
- ¿Podría deshabilitarse temporalmente la alerta, con un recordatorio establecido con una alerta configurada para cuando se espere que el problema esté completamente resuelto?
Los sistemas críticos deberían ser redundantes
Muchas emergencias de alta prioridad se pueden convertir en situaciones de baja prioridad si existe una política y práctica que establezca que todos los sistemas críticos son redundantes.
Para servidores no críticos, usa una función como la que ofrece Amazon Web Services para detectar cuando el hardware subyacente falla. Luego, puede reaprovisionar automáticamente nuevo hardware y reiniciar el servidor. Eso es exactamente lo que haría un humano de guardia en esas situaciones, así que automatiza la solución.
El primer responsable debería poder resolver la mayoría de los problemas.
Para las alertas de una aplicación en particular, alguien familiarizado con la aplicación debería estar de turno para darle soporte. Los miembros nuevos del equipo de turno pueden acompañar a los miembros con más experiencia para adquirir conocimientos antes de tomar turnos solos.
Debería haber un segundo de turno
Si el principal no responde a tiempo, las alertas deberían pasar a otra persona. Hay que dejar bien clara la responsabilidad de cada rol. Se espera que el principal se encargue de las páginas o que haga arreglos con anticipación si hay un período en el que no pueda cubrir. Que dos personas estén de turno esperando que la otra tome una página no es una estrategia.
Tener un runbook que documente las posibles alertas y las respuestas comunes a ellas
Idealmente, para cada problema debería haber alguna forma de evitar que ocurra o automatizar una solución para los incidentes. Para el resto, algunos documentos y una lista de verificación son lo mejor. He usado un Google Doc organizado por servidor o servicio. Para cada uno, hay una breve sección de Contexto para recordar qué hace la cosa, una sección de Contacto para los expertos del servicio a quienes escalar. En algunos casos, las escaladas a estas personas se pueden automatizar con el servicio de paginación. Finalmente, si hay alguna nota especial sobre alertas y resoluciones comunes. Por ejemplo:
Servidor del blog: El alto uso de CPU en este servidor a menudo indica que WordPress está siendo atacado de nuevo. Considera bloquear las direcciones IP involucradas en el firewall.
Aún mejor: usa las herramientas en servicios como PagerDuty para incluir o enlazar la documentación que necesites para cada alerta directamente en la alerta misma.
Los incidentes de producción deberían ser analizados
Ah, no hay nada como el compañerismo que surge de vivir un "firefight" para volver a poner un servicio en línea juntos.
Para minimizar las reuniones de tu brigada de bomberos, aprende de los errores cometidos y toma medidas proactivas para minimizar su recurrencia. Cuando haya una interrupción significativa, programa un informe post-incidente de producción dentro de una o dos semanas después del incidente. El enfoque es prospectivo para mejorar los sistemas. No es una sesión para buscar culpables. Usa una plantilla estándar y limita el tiempo de las reuniones para mantener las cosas en movimiento. Treinta minutos suelen ser suficientes. Aquí hay algunas preguntas que he usado antes en plantillas de informes post-incidente de producción que han resistido la prueba del tiempo:
- Resumen y cronología del incidente
- Acciones ya tomadas
- ¿Qué salió bien?
- ¿Cómo podemos prevenir incidentes similares en el futuro?
- ¿Cómo podemos responder de manera más eficiente y efectiva?
- ¿Qué acciones de seguimiento se deben tomar?
Haz que una persona cercana al incidente redacte la cronología y dirija la reunión. Invita a todas las partes interesadas relevantes para el incidente.
Todo lo demás también importa
Detallar todo lo demás que podría mejorar la calidad de vida de los respondedores de guardia sería describir un departamento de TI completo y bien gestionado.
Siempre habrá inconvenientes al estar de guardia. Con algunos principios sólidos y un compromiso con la mejora continua, hay esperanza de llegar al punto en que el número de alertas sea mínimo... y accionable.
Más contenido:
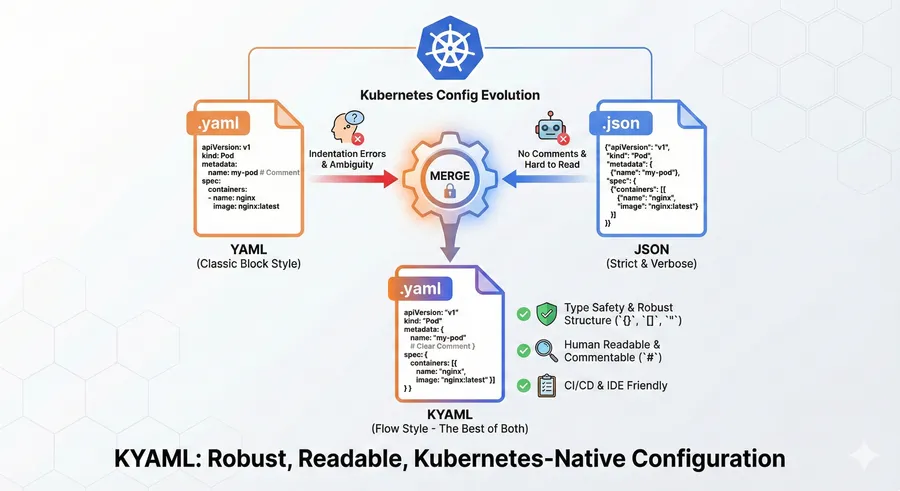
KYAML: Convergencia entre la robustez de JSON y la flexibilidad de YAML en Kubernetes
En la gestión operativa de Kubernetes, la definición de manifiestos ha oscilado históricamente entre dos extremos. Por un lado, YAML, el estándar de facto, ofrece legibilidad humana pero es intrínsecamente frágil debido a su dependencia de la indentación y la ambigüedad en el tipado de datos. Por otro lado, JSON,
Leer más →

Qué es kuberc? Es tu mejor aliado para personalizar kubectl
kuberc te permite definir preferencias de usuario, aliases de comandos y políticas de seguridad sin "dejar la crema" en tu kubeconfig con datos que no son del clúster.
Leer más →
 Mark Stosberg
Ver más contenido por Mark Stosberg
Mark tiene más de dos décadas de experiencia con DevOps y escribe blogs en inglés sobre tecnología, mapeo y otros temas en su blog en https://mark.stosberg.com/
Mark Stosberg
Ver más contenido por Mark Stosberg
Mark tiene más de dos décadas de experiencia con DevOps y escribe blogs en inglés sobre tecnología, mapeo y otros temas en su blog en https://mark.stosberg.com/